Hemos llegado al último post de la guía que comenzamos para la replicación en PostgreSql 9.3 para Linux Centos.
- Replicación en PostgreSQL – Parte 1
- Replicación en PostgreSQL – Parte 2
- Replicación en PostgreSQL – Parte 3
Siguiendo lo realizado en la última entrada, ahora debemos reiniciar el servicio de PostgreSQL:
postgresql-9.3 restart;
En CentOS-Esclavo, el fichero de configuración de postgresql.conf debe quedar de la siguiente manera:

Como puedes ver, la primera línea coincide con el servidor maestro.
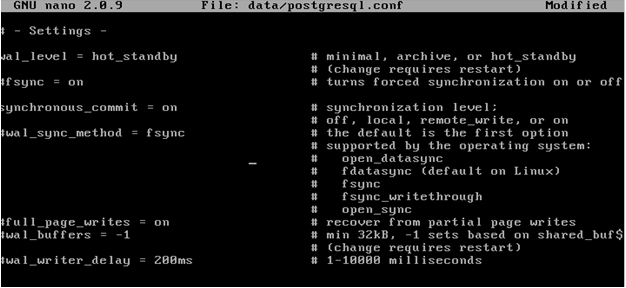


Observa que los últimos parámetros coinciden completamente con el servidor maestro.

Una vez configurado postgresql.conf, crea un archivo en el directorio data llamado recovery. conf con los siguientes datos:

Vamos a explicar línea por línea lo que hemos hecho en la anterior captura:
- standby_mode activa el modo standby en nuestro servidor standby.
- primary_conninfo contiene información necesaria para que nuestro servidor se conecte al servidor maestro .
- Con trigger_file definimos la ruta en la que se creará el fichero del trigger standby.
- restore_command se encarga de copiar los ficheros log de la carpeta archive dentro de carpeta principal de PostgreSQL, sustituyendo así los ficheros log existentes.
Ahora reiniciamos el servicio en el maestro y lo detenemos en el esclavo para realizar después una replicación automática con el comando : sudo –u postgres /usr/bin/scp /var/lib/pgsql/9.3/data/%p postgres@192.168.1.11/var/lib/pgsql/9.3/archive/%f
Ya sólo toca probar la replicación. Así, nos conectamos con el usuarios postgres en modo root y después con el comando “psql –l” vemos todas las bases de datos que tenemos creadas en el servidor maestro:
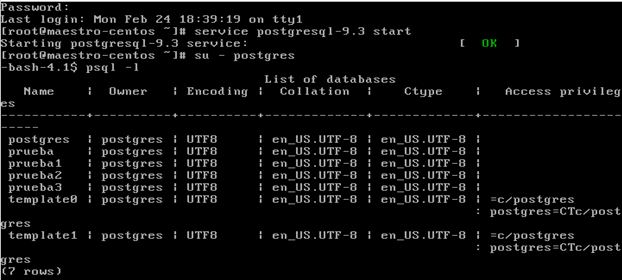
Después creamos una base de datos nueva que se llamará prueba 5: “create database prueba5;” :

Finalmente, iniciamos el servicio en el esclavo con el comando “service postgresql-9.3 start” para que nuestro servidor esclavo replique los datos del servidor maestro. Si usas el comando “psql –l” en el esclavo puedes ver como todas las bases de datos coinciden con el servidor maestro, incluida la que acabamos de crear.
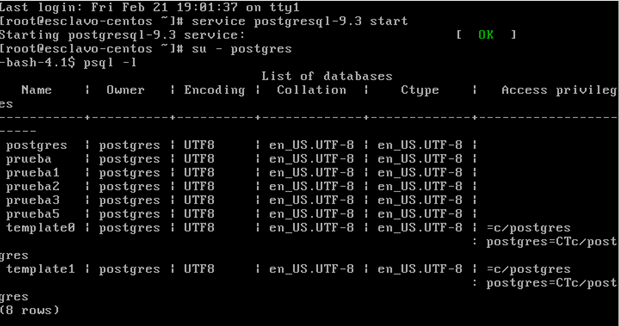
¡Y listo, ya tenemos replicada la base de datos de manera automática! A través de los procesos en ejecución puedes observar como se ha realizando la replicación en el servidor esclavo:

Esperamos que nuestro artículo te haya sido de utilidad y que no te haya resultado demasiado complejo.
Recuerda que si estás interesado en seguir ampliando conocimientos sobre bases de datos, cada jueves tenemos un podcast llamado “Aprende a Programar, el Podcast” donde hablamos sobre bases de datos, por ejemplo, en el episodio 15 estuvimos hablando sobre las certificaciones que nos encontramos en PostgreSQL
También tenemos un curso introductorio sobre PostgreSQL donde aprenderás a instalarlo en Ubuntu, Windows, MacOS, CentOS, es decir, en diferentes plataformas disponibles.
Y para usuarios avanzados, también tenemos más formación en Todo PostgreSQL, donde podrás ser un master en PostgreSQL con sus cursos.
Etaba Bueno pero en la parte del esclavo las ultimas imagenes están cortadas, se replica la misma configuracion que del servidor maestro???
Gracias por escribir Romulo, en las últimas imágenes podemos observar que si creamos una base de datos en el maestro, en el esclavo también deben de aparecer y en la última estamos viendo que hay un proceso que está realizando el recovering, es decir, encargado de la sincronización.
Saludos y gracias por visitarnos.
buenas noche compañero muy bueno tutorial una una pregunta puedo colocar a replicar 1 base de datos en postgresql 9.4 de 153 gigas en postgresql